私は現在レコメンデーションに興味があり、LLMを用いて知識グラフ上の経路から説明を可能にしているという非常に面白い論文があったので、今回はそちらを紹介します。また、同じく初学者の視点から、数式などの詳細な解説は控え、主に論文中の図や表を元に直感的な理解を目指して解説を進めていきたいと思います。そのため、もし内容に間違いなどありましたら、ご指摘いただけますと幸いです。
取り上げるのは、Path Language Modeling over Knowledge Graphs for Explainable Recommendationです。この論文の主要なアイデアと結果を、論文中の図表を交えながら解説していきます。
はじめに
ユーザーに何かを推薦する際、なぜそのアイテムが推薦されたのかという「説明」は非常に重要です。特に、知識グラフ(KG)はユーザーとアイテムに関する包括的な情報を含んでおり、説明可能なレコメンデーションを実現するために広く活用されています。既存の多くの手法では、知識グラフ上のノードを辿ることで、ユーザーと推薦アイテム間の経路を導き出し、これを説明として提示します。この経路は、ユーザーの過去の行動パターンを反映するものとなります。
しかし、従来の手法には課題がありました。構築された知識グラフ内の接続のみを辿るため、経路が存在しないアイテムは原理的に推薦され得ないという「リコールバイアス」の問題です。つまり、知識グラフの構造(グラフのトポロジー)によって推薦できるアイテムが制限されてしまうのです。
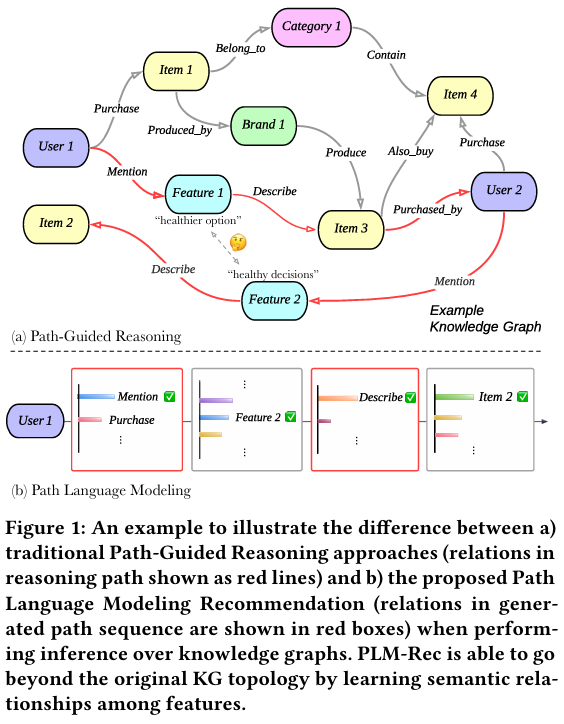
Figure 1は、従来の経路誘導推論 (Path-Guided Reasoning) と本論文で提案されている経路言語モデリング (Path Language Modeling) の違いを示しています。従来のPath-Guided Reasoningでは、知識グラフ内の既存の繋がり(赤い線)を辿って推論を行います。これに対し、提案手法であるPLM-Recは、特徴間の意味的な関係性を学習することで、元の知識グラフのトポロジーを超えることが可能になります。
提案手法(PLM-Rec)
このリコールバイアスの問題を解決するため、本論文ではPLM-Recという新しいフレームワークを提案しています。PLM-Recは、知識グラフ上のエンティティ(ユーザー、アイテム、属性など)とエッジ(関係性)からなる経路に対して言語モデルを学習します。

Figure 2は、PLM-Recフレームワークの概要を示しています。
(a) まず、知識グラフGが存在します。
(b) 次に、様々なホップ数制約のもとで訓練用の経路系列 S(u,v) を抽出します。意味的に類似した特徴量に対する拡張も活用されます。
(c) そして、Transformerベースのデコーダを用いて自己回帰的な経路言語モデル ϕ(⋅) を訓練します。
(d) 最後に、テストユーザーに対して経路生成と推薦を行う全体のパイプラインが示されています。
経路系列のデコーディングを通じて、PLM-Recは推薦と説明生成を単一のステップで同時に行います。これにより、ユーザーの行動を捉えるだけでなく、既存の知識グラフの接続への依存を排除し、前述のリコールバイアスを軽減することができます。さらに、この技術は知識グラフが疎であったり、多数の関係性を持つ場合でも説明可能な推薦を可能にします。
リコールバイアスの定量化
論文では、まず既存の知識グラフベースの説明可能な推薦手法におけるリコールバイアスの存在をデータ駆動的に検証し、その度合いを定量化しています。
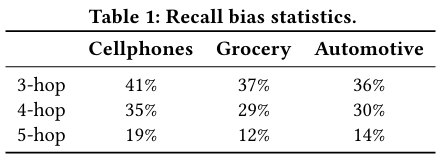
Table 1は、3つのAmazonデータセット(Cellphones, Grocery, Automotive)におけるリコールバイアスの統計を示しています。例えばCellphonesデータセットでは、3ホップ以内で到達できないアイテムの割合が41%にも上ることが示されています。これは、知識グラフの接続のみに頼る従来手法では、多くのアイテムが推薦候補から漏れてしまう可能性を示唆しています。
知識グラフベースの説明モデルがどの程度リコールバイアスを軽減できるかを測定するための新しい指標として、NR2 (New Reach Ratio) が提案されています。
実験と結果
提案手法PLM-Recの有効性を示すために、3つの実世界のAmazon eコマースデータセット(Cellphone, Grocery, Automotive)を用いて広範な実験とアブレーションスタディが行われています。

Table 2は、実験に使用されたデータセットの基本統計量を示しています。ユーザー数、アイテム数、インタラクション数、スパース性、エンティティ数、関係数、トリプル数がまとめられています。例えばAutomotiveデータセットは他の2つと比較してスパース性が高く(密度が低い)、関係の種類も多いことが分かります。
ベースラインとの比較
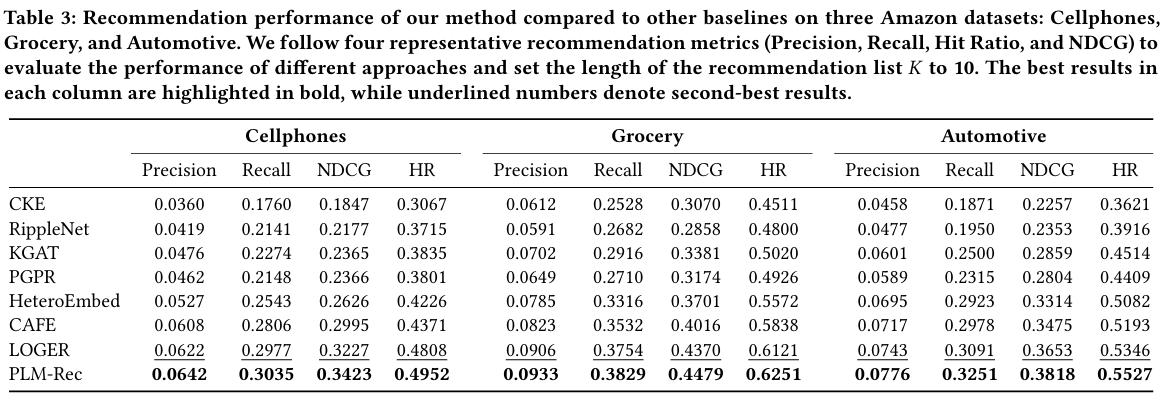
Table 3は、PLM-Recと7つの代表的な最新の推薦手法との性能比較を示しています。評価指標にはPrecision, Recall, NDCG, Hit Ratio (HR) が用いられ、推薦リストの長さKは10に設定されています。結果として、PLM-Recは全てのデータセット、全ての評価指標において、既存のKGベースの埋め込み手法や経路ベースの推論手法を上回る最高の性能を達成しています。特に、Automotiveのようなスパースなデータセットにおいて、PLM-Recの優位性が顕著であり、これはKGの意味空間を探索することで潜在的な接続を発見する能力によるものだと考察されています。
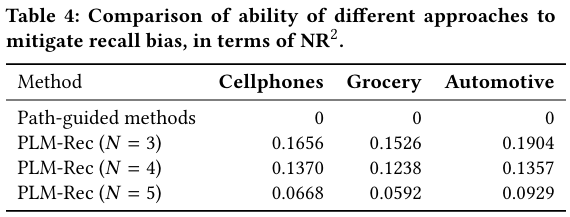
Table 4は、異なるアプローチがリコールバイアスを軽減する能力をNR2で比較しています。PLM-Recは、従来の経路誘導手法(Path-guided methods)と比較して、固定された経路長の下で知識グラフのトポロジーの制約を大幅に打ち破り、より多くの真のアイテムに到達できることを示しています。例えば、CellphonesデータセットにおいてN=3の場合、PLM-Recは0.1656のNR2値を達成しています。
アブレーションスタディ
論文では、経路長、系列拡張、デコーディング戦略といった要素がPLM-Recの性能にどのように影響するかを詳細に分析しています。
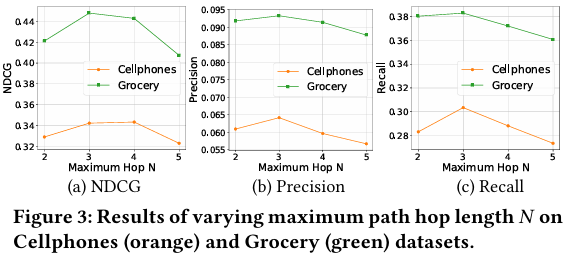
Figure 3は、最大経路ホップ数Nを変化させた場合の結果を示しています。NDCG、Precision、Recallのいずれの指標も、N=3の時にピークに達する傾向が見られます。これは、経路が長すぎるとノイズの多いエンティティが含まれる可能性があり、短すぎると十分な情報が得られないことを示唆しています。
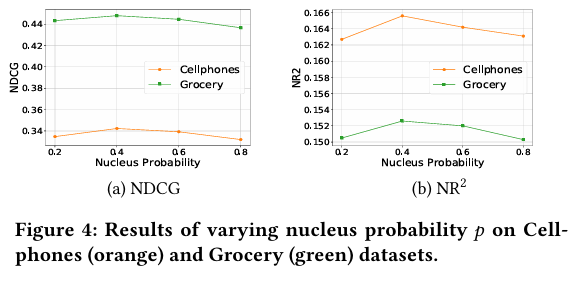
Figure 4は、デコーディング戦略の一つであるNucleus Samplingにおける核確率pを変化させた場合の結果を示しています。pが0.4付近で最適な性能が得られることが分かります。
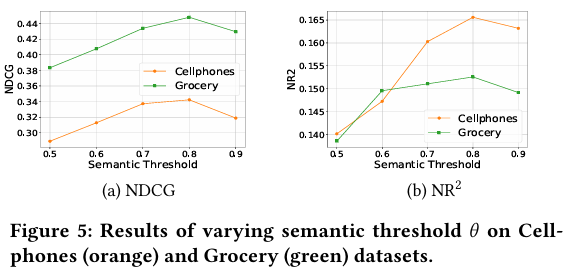
Figure 5は、系列拡張に用いる意味的類似度の閾値θを変化させた場合の結果を示しています。θが0.8の時にNDCGとNR2の両方で最良の結果が得られています。
ケーススタディ
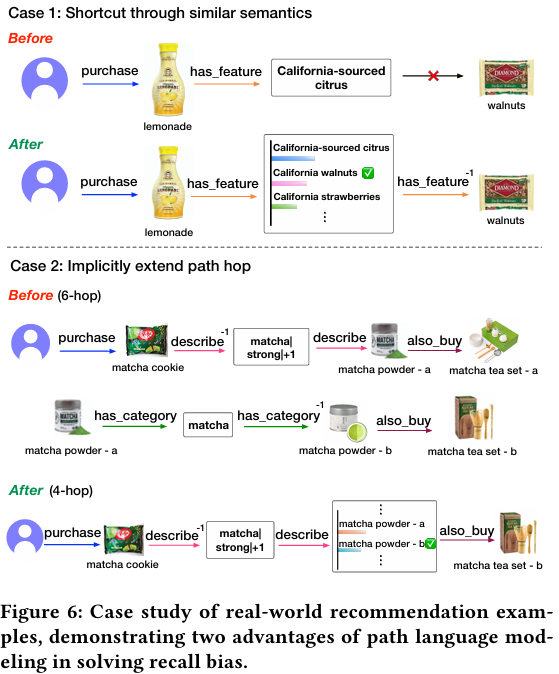
Figure 6は、PLM-Recがどのようにリコールバイアスを軽減するかを示す実際の推薦例です。
ケース1「類似した意味論によるショートカット」では、ユーザーが以前「カリフォルニア産の柑橘類」という特徴を持つレモネードを購入した履歴があります。PLM-Recは、このユーザーがカリフォルニア製品を好むという潜在的なパターンを捉え、「クルミ」を推薦します。元のKGでは3ホップではクルミに到達できませんでしたが、PLM-Recは意味を学習しショートカットを推論することで推薦を可能にしています。
ケース2「経路ホップの暗黙的な拡張」では、濃い抹茶フレーバーを好むユーザーに抹茶関連の器具を推薦する例です。抹茶器具はGroceryデータセット内では直接的な繋がりが少ないカテゴリに属しているため、既存のKGリンクを辿る場合は6ホップ必要でした。しかし、PLM-Recは同じカテゴリの製品に関する知識を訓練中に吸収するため、4ホップで推薦アイテムに到達できています。これは、PLM-Recが意味的な汎化能力を獲得することで、暗黙的に経路ホップを拡張できることを示しています。
まとめ
本論文「Path Language Modeling over Knowledge Graphs for Explainable Recommendation」は、知識グラフを用いた説明可能なレコメンデーションにおけるリコールバイアスという重要な問題に着目し、経路言語モデリングという新しいアプローチを提案しました。PLM-Recフレームワークは、知識グラフのトポロジーに縛られることなく、推薦と説明生成を同時に行い、リコールバイアスを効果的に軽減します。広範な実験により、その有効性と汎化能力が実証されており、説明可能なレコメンデーションの分野に新たな視点を提供する非常に興味深い研究だと感じました。
今後、LLMの発展とともに、このような経路言語モデリングの考え方は、レコメンデーションシステムや検索システムにおいてますます重要になっていくのではないでしょうか。
📝 用語解説
- グラフのトポロジー (Graph Topology)
グラフ理論における「トポロジー」とは、グラフの構造的な性質、つまりノード(点)がエッジ(線)によってどのようにつながっているか、その接続関係のパターンや配置を指します。レコメンデーションシステムの文脈では、知識グラフのトポロジーは、ユーザー、アイテム、属性といったエンティティがどのような関係性で結びついているかの全体像を示します。このトポロジーが、推薦アルゴリズムがアイテムを発見する際の「道筋」を決定づけるため、非常に重要になります。「元の知識グラフのトポロジーを超える」とは、知識グラフに明示的に存在しないエンティティ間の新しい関連性(経路)を推論によって見つけ出すことを意味します。
- NR2 (New Reach Ratio / 新規到達率)
この論文で提案されている評価指標で、モデルが知識グラフの既存の経路探索では到達できなかったアイテムのうち、どれだけ多くの正解アイテムを新たに推薦できたかを示す割合です。具体的には、各ユーザーに対して、モデルが推薦した上位K件のアイテムの中に含まれる「新規に発見された正解アイテム数」を、そのユーザーの上位K件の推薦結果に含まれる「全ての正解アイテム数」で割ったものの平均値として計算されます。この値が高いほど、モデルがリコールバイアスを軽減し、より多様なアイテムを推薦できる能力を持つことを示します。
参考文献
- Geng, S., Fu, Z., Tan, J., Ge, Y., de Melo, G., & Zhang, Y. (2022). Path Language Modeling over Knowledge Graphs for Explainable Recommendation. In Proceedings of the ACM Web Conference 2022 (WWW '22) ACM.